EOPEN Ontology: Annotation model for social media and change detection
The EOPEN Annotation Model is a structured model and format to enable annotations and assertions to be defined, shared and reused across both inside the EOPEN application context but also in different hardware and software platforms. This is achieved as the model is based on the Web Annotation Data Model (WADM) standard. The annotation model is able to represent:
- social media related metadata coming after twitter analysis (i.e. tweets, topics, events)
- change detection information (i.e. flood maps).
The model also inherits properties and classes from GeoSPARQL in order to represent geospatial information (i.e. polygons, points).
Representing Social Media
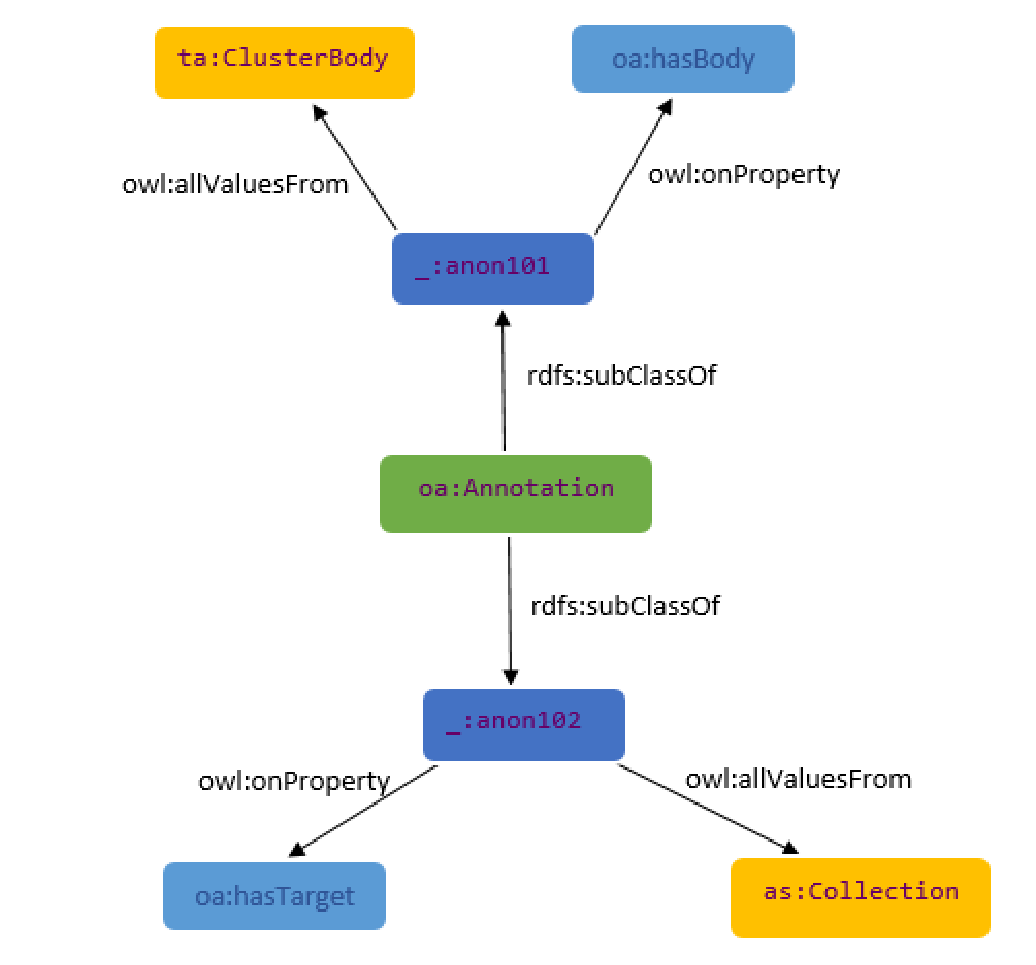
The figure below formally depicts the relationship between the Annotations, which we inherit from WADM, and the other classes of the ontology. More specifically, EOPEN uses the oa:Annotation class as a basic class in the ontology. The class is used in both oa:Annotation and ta:Cluster_Annotation instances as a root. The initiation of an annotation relevant to cluster annotation is performed by defining instances of the oa:Annotation class.
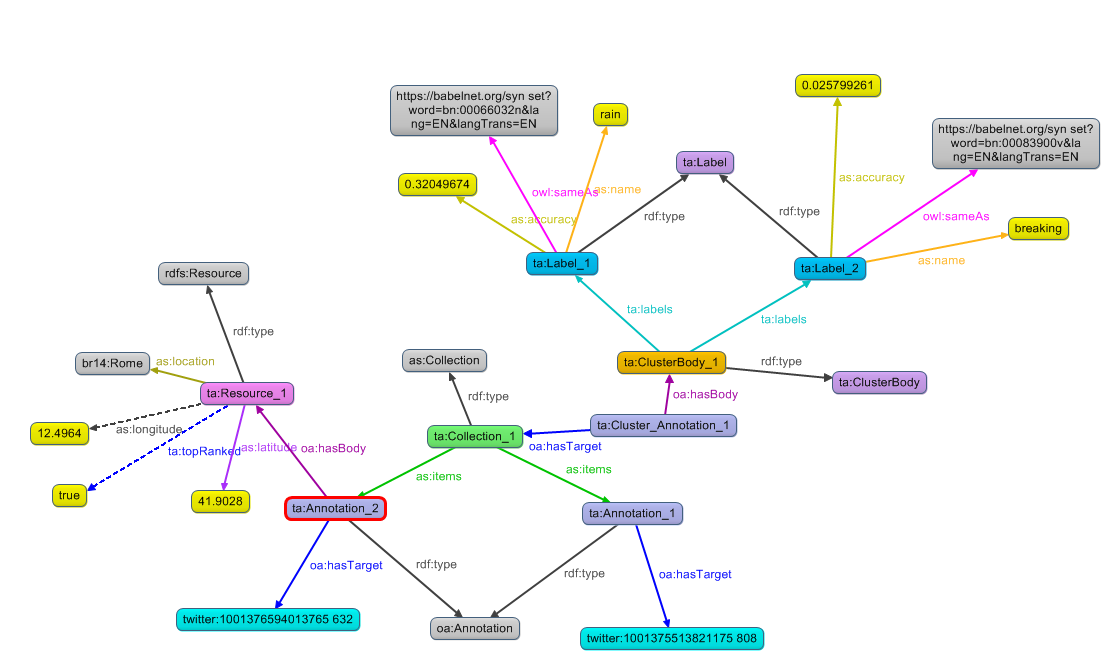
The figure below provides a full example of mapping the twitter analysis results following the abovementioned relationship. More specifically, a ta:ClusterAnnotation resource is generated that is linked with the target of the annotation, i.e. the generated collection (ta:Collection_1) and the cluster body (ta:ClusterBody_1). The latter, defines property assertions relevant to the labels extracted from the tweet, the connected BabelNet synsets and the accuracy, while the first defines the tweet general information like URL, location (i.e. latitude and longitude) and topRanked property.
Representing Change Detection
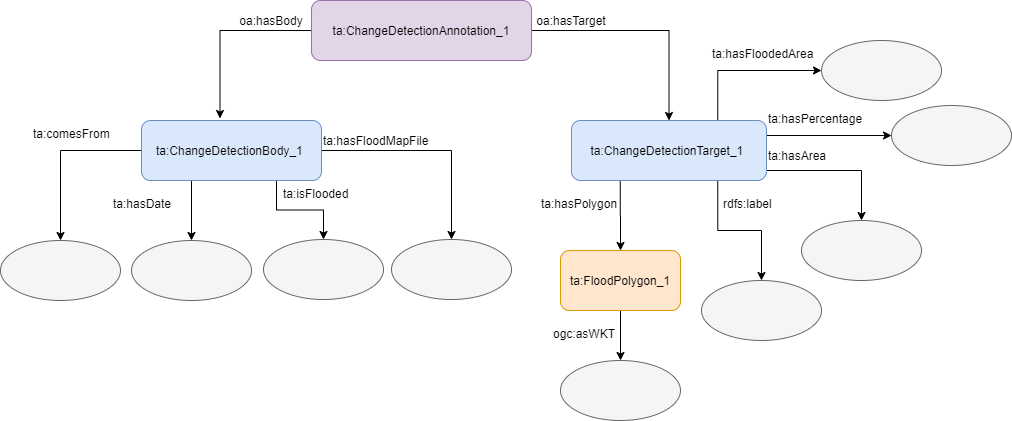
Change detection information are mapped using a ta:ChangeDetectionAnnotation class instance. The instance allows a connection establishment between a change detection target (target) and a change detection body (body). The first contains all flooded area information (i.e. percentage, area, flood polygon, etc.) while the latter contains more generic information like date, flood map file, the sentinel that the image comes from, etc. The schema of what has been described is shown in the figure below. The circular grey components show the data properties and the existence of values in specific properties which may be of type String, Integer, etc.
In order to develop the abovementioned ontologies and knowledge representation structures, we have been based on the following tools:
- Protégé-OWL v5.0, a popular tool for designing and developing ontologies;
- Web Ontology Language (OWL), a knowledge representation language for ontology definition;
- RDF4J, a Java library that allows handling RDF data;
- GraphDB to host the knowledge base environment;
- SPARQL to support semantic queries and reasoning rules execution;
- GeoSPARQL as the semantic query language for executing geospatial queries;
- Babelfy, BabelNet and WordNet to semantically enrich the content by detecting similarity in terms.
License
Apache License 2.0
Publications
- Rousi, M., Sitokonstantinou, V., Meditskos, G., Papoutsis, I., Gialampoukidis, I., Koukos, A. Karathanassi, V., Drivas, T., Vrochidis, S., Kontoes, C., Kompatsiaris, I. (2020). Semantically enriched crop type classification and Linked Earth Observation Data to support the Common Agricultural Policy monitoring. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing.
Related Projects
- EOPEN
Ontologies (links)
https://drive.google.com/file/d/1Ncabdo7hRA7CQRttpkZoKjThLe8G6dfP/view?usp=sharing
Contact
- Maria Rousi: mariarousi@iti.gr
- Georgios Meditskos: gmeditsk@iti.gr