Object Detection Tool
The Object Detection Tool focuses on recognizing objects (e.g., cars, boats etc.) from visual content captured from various optical sources/sensors such as cameras mounted on UAVs, CCTVs etc. The tool involves two interconnected layers: (i) image classification which refers to the prediction of the object’s class and the corresponding confidence score and (ii) localization of the object in the image plane through the prediction of a bounding box that encloses each detected instance.

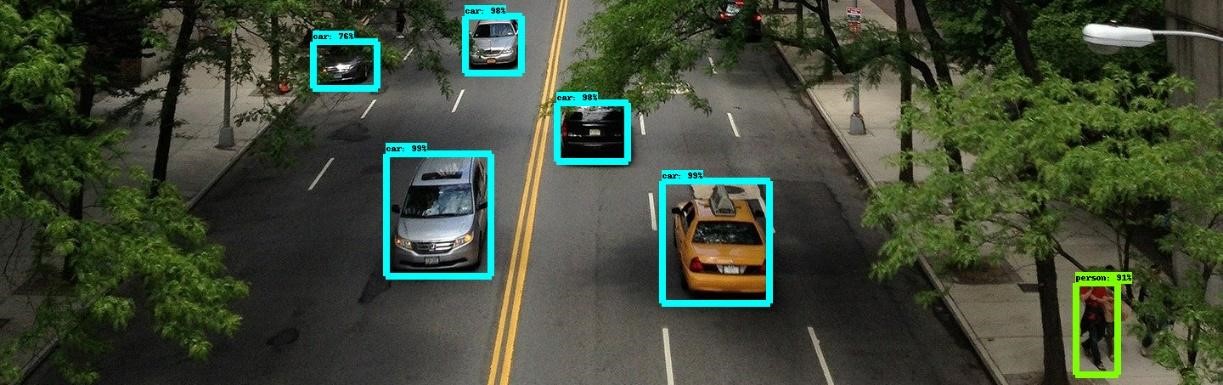

The Object Detection Tool relies on the continuous and on-going research work of our group [1]. A general-purpose object detector is initially focused on objects being acquired on a first-person perspective. Nonetheless, the concurrent progress in the field of robotics demands the development of special-purpose algorithms aiming at implementation in systems with lower resources available and/or processing aerial images from UAVs [2]. As a result, the Object Detection Tool can also be utilized for more sophisticated perspectives and acquisition angles such as from UAVs where camera’s position is dynamically changing.
The service involves a specialized trained Faster RCNN [3], which has been proven to be highly robust and produce a well-generalized and effective model, with a Resnet101 [4] backbone to report an inference time of 106ms per image on COCO dataset. The tool was trained with approximately 20.000 images from publicly available datasets such as UAV123, VisDrone, Virat and UCF aerial action datasets and private datasets to further improve the accuracy of the detected objects of interest. The objects of interest setlist includes a generic class for people, and for most common land, (e.g. cars, trucks, buses, motorcycles) and maritime vehicles (e.g. regular boats, ships, speedboats, inflated boats). The datasets for the training process of the model relied on cameras with fixed location (specific point and height), cameras under motion (e.g. hand-held, mobile phones etc.) or mounted on an UAV.
System requirements
Supported OS: Ubuntu/Windows
Processor: Any CPU with 4 cores or more
RAM: 8 GigaBytes (GB) or more
Hard drive size: 30GB of free space
Graphics card: NVIDIA GPU with 8GB memory or more for (near) real-time processing
Contact information
Georgios Orfanidis (g.orfanidis@iti.gr)
Nikolaos Dourvas (ndourvas@iti.gr)
Konstantinos Ioannidis (kioannid@iti.gr)
Stefanos Vrochidis (stefanos@iti.gr)
References
[1] G. Orfanidis, S. Apostolidis, G. Prountzos, M. Riga, A. Kapoutsis, K. Ioannidis, E. Kosmatopoulos, S. Vrochidis, I. Kompatsiaris, “Border surveillance using computer vision enabled robotic swarms for semantically enriched situational awareness”, Mediterranean Security Event, (MSE 2019), Heraklion, Greece, 29 – 31 October 2019.
[2] 23 J. Gu, T. Su, Q. Wang, X. Du, and M. Guizani, “Multiple moving targets surveillance based on a cooperative network for multi-uav,” IEEE Communications Magazine, vol. 56, no. 4, pp. 82–89, 2018.
[3] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99).
[4] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778)
Related Projects
![]()


