PatMedia is a Hybrid Retrieval Engine for retrieving patent multimedia content. Different version of the PatMedia engine are developed that incorporate different functionalities.
You can find the links for the different PatMedia search engines here and test them.
PatMedia comprises the retrieval module of an integrated patent image retrieval framework that supports automatic extraction, processing and indexing of patent figures and related metadata from patent documents. The design and implementation of this framework is tailored to the special nature of patents as it builds upon advanced techniques from image analysis and content-based retrieval to enhance the performance of patent image search. Two different versions of PatMedia have been developed.
1st version
This version incorporates the following four modes:
- Patent Browsing: based on patent information. Further options as direct patent pdf document download and drawing section page browsing are supported.
- Visual Search: based on an advanced algorithm that extracts an innovative feature for binary image retrieval named: the Adaptive Hierarchical Density Histograms, with a view to finding visually similar content.
- Text Retrieval: based on the textual description of the figures found inside the patent document. The textual description is extracted and process with the aid of text analysis, while matching of the text with the images is performed by identifying the figure label with OCR techniques.
- Hybrid Retrieval: based on combining textual information with category information that is extracted after performing text analysis on the figure descriptions.
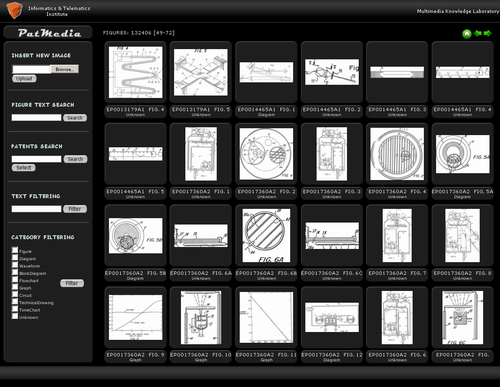
PatMedia Interface. Click on the figure for a live demonstration.
2nd version
This version is based on supervised machine learning. Specifically, the core of the developed framework consists of a Support Vector Machine structure, and different SVMs are trained to classify patent figures to a predefined set of high-level concepts. Currently, 6 concepts are supported, which are found in images belonging to patents of A43B IPC class: Cleat, Ski Boot, High Heel, Lacing Closure, Spring Heel, Tongue. The four different functionalities that are incorporated are the following:
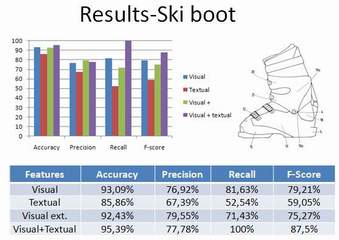
- Visual: based on visual information. Specifically the Adaptive Hierarchical Density Histograms (AHDH) [1] were extracted as feature vectors.
- Extended Visual: based on visual information. The scores provided by the classifiers employed in the visual training case formed a score vector, which was fed to a final SVM classifier structure to generate the final confidence score.
- Textual: based on textual information. A bag of words implementation was realized. Lemur [2] was employed for textual information indexing.
- Visual + Textual: based on visual and textual information. The feature vector generated was a concatenation of AHDH and bag of words vectors.


PatMedia concept extraction demo. Click on the figure for a live demonstration.
Conferences and Events
PatMedia was presented and evaluated in the following patent related events and conferences:
- Gerard Ypma, “Evaluation of Patent Image Retrieval“, Information Retrieval Facility Symposium 2010 (IRFS 2010), Vienna, Austria, June 1-4, 2010.
- Jane List, “Review of ITI Approach for Searching Non-Text Information in Patents“, Information Retrieval Facility Symposium 2010 (IRFS 2010), Vienna, Austria, June 1-4, 2010.
- Stefanos Vrochidis, “Towards Patent Image Retrieval“, International Patent Information Conference & Exposition, IPI-ConfEx 2009, Venice, Italy, March 1-4, 2009.
- Stefanos Vrochidis, “Patent Image Retrieval“, Information Retrieval Facility Symposium 2008 (IRFS 2008), Vienna, Austria, November 5-7, 2008.
- Joan Codina, Emanuele Pianta, Stefanos Vrochidis and Symeon Papadopoulos, “Integration of Semantic, Metadata and Image search engines with a text search engine for patent retrieval”, Semantic Search 2008 Workshop, Tenerife, Spain, June 2, 2008.
This work was supported by the projects PATExpert and CHORUS “Coordinated approacH to the EurOpean effoRt on aUdiovisual Search engines” both funded by the European Commission.
PatMedia in the Web
PatMedia is listed in the Information Retrieval Facility Prototype Portal.
PatMedia is evaluated by Intellogist, a place for finding patent searching expertise. Read the PatMedia review here..
References
[1] P. Sidiropoulos, S. Vrochidis, I. Kompatsiaris, “Content-Based Binary Image Retrieval using the Adaptive Hierarchical Density Histogram”, Pattern Recognition Journal, Elsevier, Volume 44, Issue 4, pp 739-750, April 2011. [2] Lemur project: http://www.lemurproject.org/