Migration is a complex and challenging phenomenon, which affects all levels of society at a local, national, regional, European, and international level. A multistakeholder approach, in combination with the development of new Information and communication technologies (ICTs) solutions is imperative on the one hand to support the smooth integration of migrant/refugees and asylum seekers to the hosting communities (as part of the 2030 Sustainable Development Agenda’s call to ‘leave noone behind’), as well as on the other hand to address any foreseen challenges related to human rights protection as well as to border security.
M4D, having actively participated in several migration related projects, aims to support the need for future development of information sharing platforms and ICT enabled migration services, compliant with security-by-design principles, as well as all with relevant ethical and legal issues. Key research and development activities of M4D in the migration domain, where it aims to capitalize on and move the research and development forward include:
- Semantic Knowledge Representation and Reasoning
- Content based Recommender Systems / Matchmaking
- Ontologies alignment with text analysis and generation requirements
- Decision support and visual analytics
- Human Computer Interaction / Conversational agents
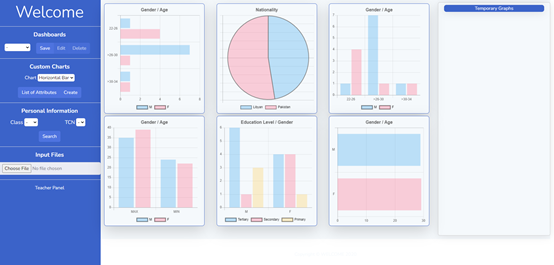
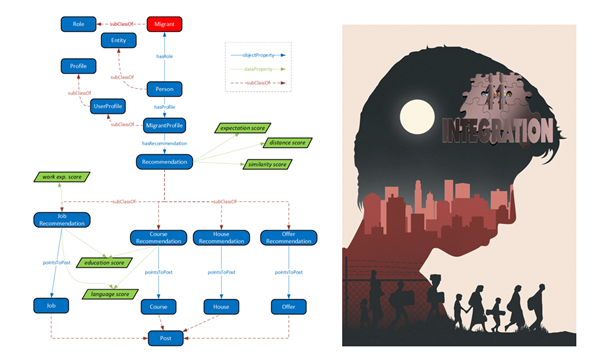
1D. Ntioudis et al., “Immerse: A Personalized System Addressing the Challenges of Migrant Integration,” 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 2020, pp. 1-6, doi: 10.1109/ICMEW46912.2020.9105981.
