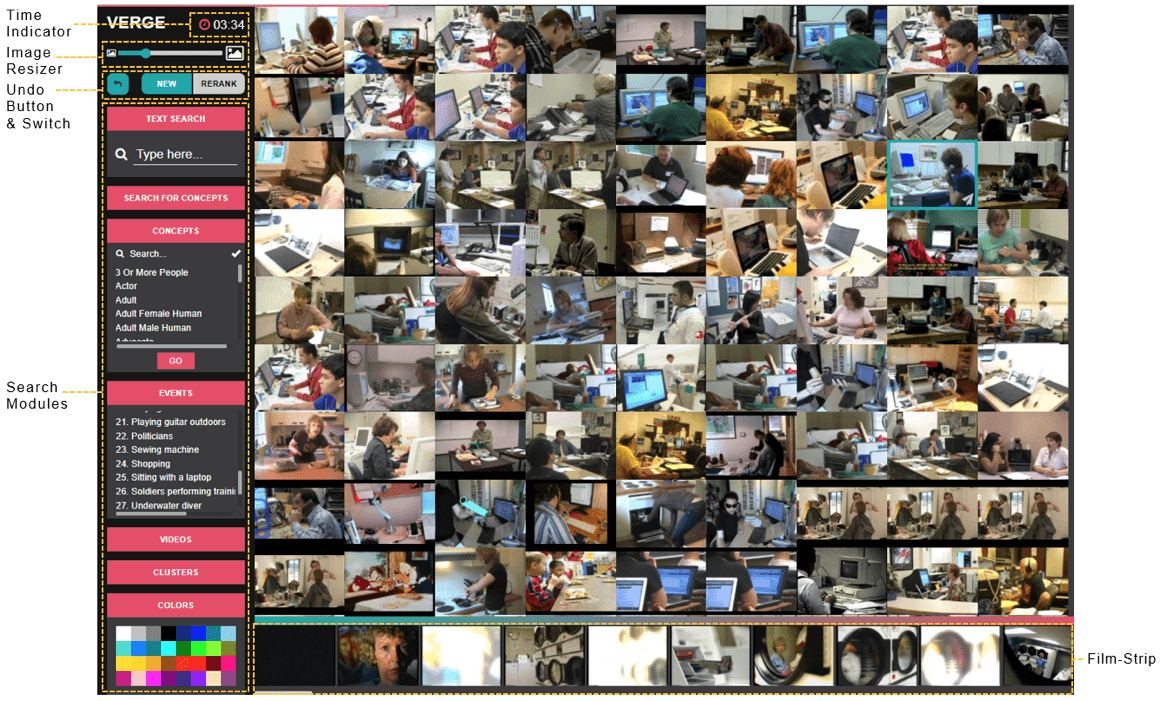
Big Data Collections (e.g. Earth Observation data, social media streams, large video collections, etc.) are characterized by large volumes, velocity and variety, due to their highly heterogeneous nature and timeliness. Multimedia retrieval requires efficient indexing of the available raw data and extracted metadata, such as concepts, visual features, textual features and mutually semantically linked multimodal objects. The multimodal character of Big Multimedia Data requires an effective combination of multiple modalities for similarity search and retrieval using compound queries. Our research focuses on the design and development of domain-specific and focused search engines with novel user interfaces, taking into account the AI-based extracted and indexed metadata per multimedia object.