In the last decade, extreme events such as flood disasters are becoming more frequent and more destructive compared with the old ones, especially in developing countries, causing loss of human lives and properties. Official researches reveal that the majority of all disaster events from 2000 to 2019 concern flooding events that have impacted 1.6 billion people worldwide. The main reasons that cause flood events to escalate to disaster are climate changes and anthropogenic factors. Therefore, proper monitoring and identification of areas that are prone to floods and also the effective mitigation countermeasures are considered very important to risk reduction.
M4D, having actively participated in several projects, develops solutions that support the identification and classification of crisis events by considering data from satellites, social media, weather forecast, and other sources. Information fusion and intelligent machine learning and deep learning methods are employed for exploiting the synergy in the acquired information and produce timely and accurate estimations of crisis level and the risk assessment.
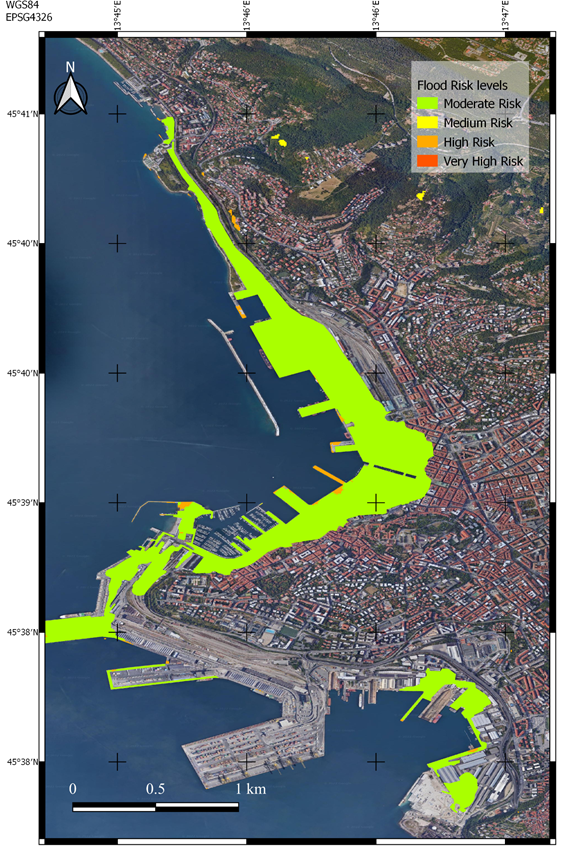
Flood Risk map for Trieste on September 23, 2019

Flood Hazard map for Trieste on September 23, 2019

